Well written, just one update:-
Document why we can’t use TIDL to accelerate transformer layers on BeagleBone AI-64 and BeagleY-AI, and outline the potential next steps.
Well written, just one update:-
Document why we can’t use TIDL to accelerate transformer layers on BeagleBone AI-64 and BeagleY-AI, and outline the potential next steps.
Weekly Update
Here is my update for this week:
Progress
docker-compose setup to host the API, enabling users to deploy the retrieval system locally with minimal dependencies.Blockers
Next Steps
Note
I will be unavailable for next week’s update as I will be traveling to China tomorrow to lead the Tunisian delegation participating in the International Olympiad in Artificial Intelligence (IOAI).
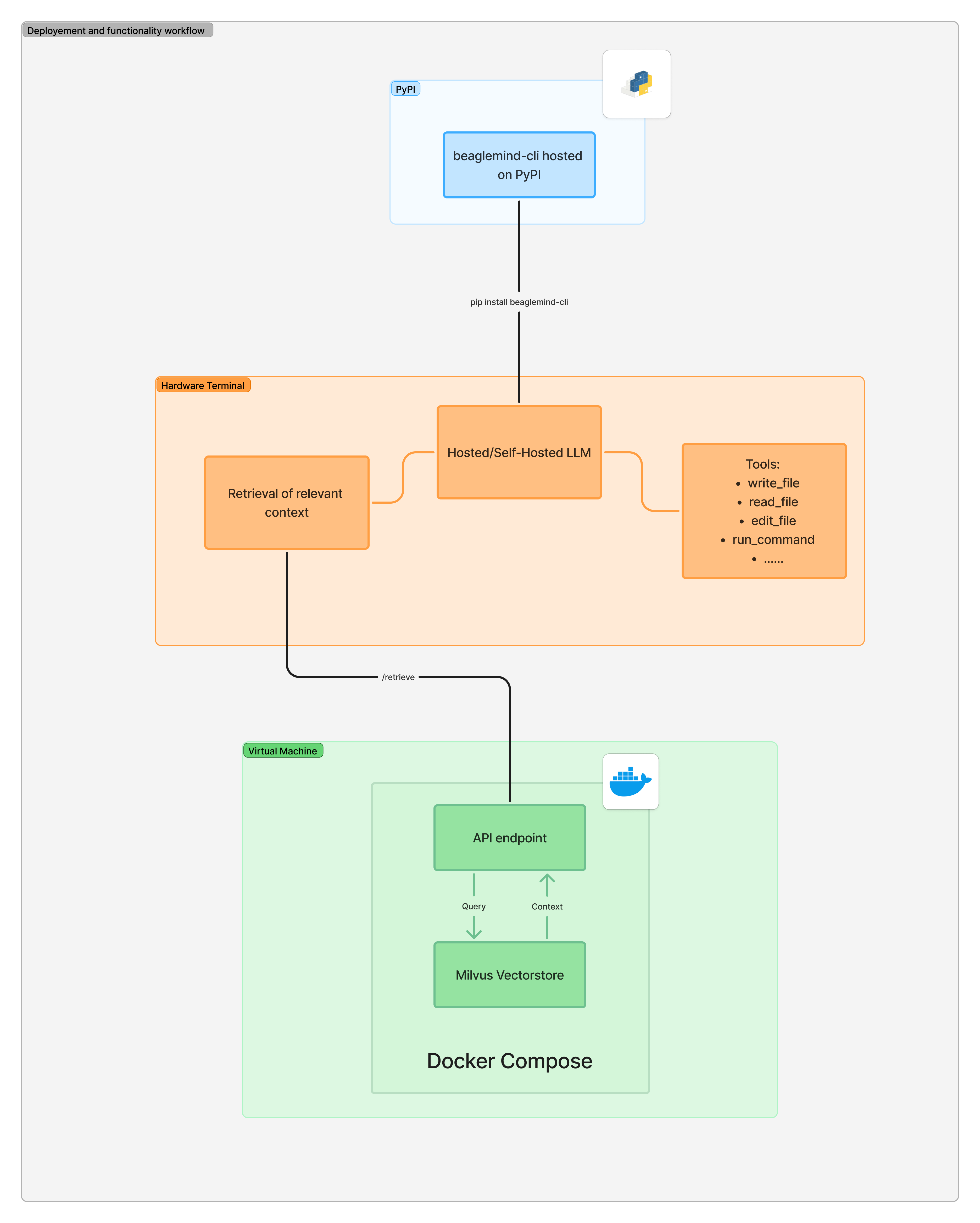
Hi, this is a small update on the deployment phase, here’s how I’m planning to deploy each component of the project:
Hi, in this message I would like to share the preffered specification for the deployment machine
This message outlines the deployment specifications for a virtual machine (VM) that will host a FastAPI-based API endpoint with a Milvus vector database. The system will use Docker Compose to manage four containers:
The VM must be configured to ensure smooth operation, scalability, and sufficient storage for vector embeddings (up to 30 GB).
8000 (FastAPI), 9001 (MinIO), 2379 (ETCD) and 19530 (Milvus) exposed.| Resource | Minimum Spec | Recommended Spec | Notes |
|---|---|---|---|
| CPU | 2 Cores | 4 Cores | Milvus benefits from multiple cores for query processing. |
| RAM | 8 GB | 16 GB | Milvus and etcd are memory-intensive. |
| Storage | 50 GB SSD | 100 GB SSD | 30 GB for data + buffer for logs, MinIO, and OS. |
| Swap | 4 GB | 8 GB | Helps with memory spikes. |
Total Recommended Storage: 50 GB (Minimum), 100 GB (Scalable).
Note: I think we can go for the minimum specs since the fetched data from the repositories don’t take that much space and require just a few gega bytes of storage.
This setup ensures a scalable and efficient deployment of a FastAPI endpoint with Milvus for vector search. Adjust resources as data grows.
Next Steps:
htop, docker stats, or even using Kubernetes for high level monitoring).Let me know if you need adjustments! ^^
Nice!
Both boards are based on TI’s Jacinto 7 SoCs (BeagleY-AI: AM67A (J722S); BeagleBone AI‑64: TDA4VM (J721E)). In TI’s Processor-SDK Edge AI, both processors support the TI Deep Learning (TIDL) library and tools github.com. For example, a user reported that on the AM67A (BeagleY-AI) board using Processor-SDK Linux v10.00.00.08, the included TIDL version is 10.00.04.00 e2e.ti.com. (The TDA4VM board similarly runs SDK 10.x, which includes a comparable TIDL release.) In short, TIDL 10.x is the supported toolchain on both boards, enabling the TI DL runtime to leverage the C7x DSP and MMA accelerators when properly enabled github.come2e.ti.com.
TI’s TIDL library has limited support for transformer operations, primarily oriented toward vision models. As TI’s documentation explains, starting in SDK 9.1 TIDL added support for basic Vision Transformer (ViT) models and layers: it supports multi-head attention, LayerNorm, SoftMax and similar blocks used in image-classification transformers e2e.ti.com. Release notes for newer TIDL versions (v10.1.4) explicitly highlight improvements for “transformer-based architectures”: e.g. fixed-point acceleration of LayerNorm, SoftMax, Concat and Add, and enhanced accuracy for vision transformer backbones like Swin, DeiT and LeViT github.com. However, this support is aimed at vision transformers (image tasks). TIDL does not provide a general-purpose transformer accelerator for large language models; it does not, for example, implement all the attention/embedding/gather operations typical of an LLM. In practice, complex LLM architectures like Qwen2.5‑Coder (a large code-generation transformer) contain operators beyond TIDL’s current supported set. TI’s own forums note that only “basic transformer (classification) ViT” and “partial support of SwinT” are supported e2e.ti.com, implying that a full LLM is outside the optimized use case.
TI’s official notes and the BeagleBoard community confirm these limitations. The TI forums explicitly state that TIDL’s transformer support is restricted to certain vision tasks e2e.ti.com, and urge use of TIDL’s model-import tools with specific workarounds (e.g. ONNX opset downgrades) for ViT/DeiT networks. Moreover, BeagleBoard users have reported practical issues enabling TIDL on these boards. For instance, BeagleY-AI’s default device tree disables the C7x DSP (necessary for TIDL acceleration) in the stock image forum.beagleboard.org. Enabling the DSP requires custom overlays or modified firmware – workarounds that are nontrivial. As one community post summarized: “You will have to create a device tree overlay because the C7x is disabled in the k3-j722s base device tree. I don’t see any of that in the beagley‑ai base tree, yet.” forum.beagleboard.org. By mid-2025 no straightforward solution was reported. In short, there are no official TI/BeagleBoard statements claiming full transformer support on these boards; all evidence suggests that (a) TIDL is only partly transformer-compatible and (b) on BeagleY‑AI/AI‑64 the DSP accelerator isn’t enabled by default, so TIDL cannot transparently speed up a general LLM.
Because the TIDL toolchain on these boards cannot fully accelerate a Qwen2.5‑Coder model, the only reliable execution path is CPU-only. Ollama (the LLM runtime) falls back to running the model on the ARM cores. This is “most compatible” because it does not rely on any specialized hardware or unsupported operators. In contrast, attempting to offload Qwen2.5‑Coder to TIDL would hit unsupported layers or fail to run entirely. Running on CPU avoids all these compatibility issues, at the expense of throughput. In summary: TIDL on BeagleY-AI and AI‑64 is limited to vision-optimized models and often isn’t fully enabled on the boards, so CPU inference remains the practical choice for Ollama deployments e2e.ti.com forum.beagleboard.org.
Sources: TI Processor-SDK documentation and forums e2e.ti.com e2e.ti.com; Texas Instruments edgeai-tidl-tools release notes github.com; BeagleBoard community forums forum.beagleboard.org (see above citations).
Weekly Progress Update
Completed this week:
Current challenges:
Plan for the next two days:
Weekly Progress Update
Focus this week:
Blockers:
Next Steps:
Quick Update:
I’ve been working on getting inference running with Ollama. After experimenting and eventually setting a higher timeout limit, I finally got it working! Beaglemind can now generate responses locally through Ollama inference.
Date: 23/08/2025
Attendees: Fayez Zouari, Aryan Nanda
Progress this week
Completed the first draft of my final report (will update by end of day). Thanks to Aryan for the feedback!
Implemented login functionality + conversation history storage for each user.
Nearly finished with the evaluations; I’ll share them by end of day and include results in the updated report.
Used RAGAS (Retrieval-Augmented Generation Assessment Suite), a framework for evaluating Retrieval-Augmented Generation (RAG) systems.
Extracted and analyzed the following metrics:
Faithfulness → measures whether generated answers are consistent with the retrieved documents.
Relevance → checks if the retrieved documents are relevant to the user’s query.
Recall → evaluates the system’s ability to retrieve all the necessary information for a complete answer.
Precision → assesses how much of the retrieved content is actually useful/needed for the answer.
Correctness → evaluates whether the final generated response accurately answers the query.
Blockers
During evaluation, I concluded that ROUGE / BLEU / METEOR are not effective for RAG systems.
These metrics were originally designed for natural language generation evaluation (e.g., machine translation or summarization), where the output is expected to closely match reference text.
In RAG, however, correctness doesn’t always mean lexical overlap, the system can generate accurate answers in different wordings, which these metrics penalize heavily.
As a result, the scores were misleadingly poor.
To address this, I added the BERTScore / BertF1 metric, which measures semantic similarity rather than exact word overlap. This provided much more realistic and encouraging scores, aligning better with the actual system quality.
Next goals
Hello mentors and BeagleBoard community,
I’m sharing an update on BeagleMind, our AI assistant for BeagleBoard documentation. Our initial work with a RAG (Retrieval-Augmented Generation) system provided a solid foundation, but its performance in evaluations has been average. To achieve a higher standard of accuracy and reliability, I’ve begun exploring a more powerful approach: Supervised Fine-Tuning (SFT).
This method involves specializing a base language model by training it on a custom dataset tailored to our specific domain. My current focus is on building the pipeline for this, which involves three core steps:
1. Creating a High-Quality Dataset:
The first step is to generate a robust set of Question-Answer pairs directly from the BeagleBoard documentation. This dataset will teach the model our specific terminology, concepts, and use-cases.
2. Structuring the Training Data:
The QA pairs will be formatted using Chat Markup Language (ChatML). This involves defining a clear prompt template that includes a system role, tool definitions, and the expected conversation flow, ensuring the model learns to operate within a structured assistant framework.
3. Executing the Fine-Tune:
The final step is to use this carefully prepared dataset to fine-tune the model, aligning its responses closely with the needs of our community.
Current Progress & A Key Resource:
I am actively working on the first step of dataset creation. I’ve discovered a highly relevant research paper and framework that directly addresses this challenge:
“EasyDataset: A Unified and Extensible Framework for Synthesizing LLM Fine-Tuning Data from Unstructured Documents”
(Link: https://arxiv.org/abs/2507.04009)
This tool is designed to automate the generation of QA pairs by processing our documentation in chunks, with configurable overlap to ensure context is preserved. I am currently experimenting with it to produce our initial training dataset.
Next Steps & Open Call:
My immediate goal is to generate a high-quality dataset using EasyDataset and proceed with the initial fine-tuning experiments. I will share the outcomes and learnings as they become available.
This is an exploratory phase, and community insight is invaluable. I am very open to suggestions, feedback, or contributions. If you have experience with model fine-tuning, data synthesis, or thoughts on what constitutes an effective QA pair for our documentation, please reach out.
Thank you for your ongoing support and guidance.
Update on the CLI Configuration Persistence Feature
Hi everyone,
Following the discussion on GitHub, we’ve finalized the plan for implementing persistent configuration handling in the BeagleMind CLI.
Current behavior:
The CLI currently uses a static default_config dictionary. Any changes made during a session are lost once the user exits.
Goal:
Allow users to persist configuration preferences (like backend, model, temperature, etc.) across CLI sessions.
Proposed solution (approved by @fayezzouari):
Introduce a small ConfigManager class to handle configuration loading and saving.
On the first CLI run, if no config file exists, automatically create one at ~/.beaglemind/config.json using default values.
If no config options are specified at runtime, load from the saved JSON file.
If a user specifies config options through command arguments, use those and update the JSON file accordingly.
This structure keeps configuration logic modular, maintains persistent user preferences, and simplifies future expansions (like adding commands to view or reset configs).
I’ll begin working on the PR implementation and will keep this thread updated with progress.
— Sanchit (@SanchitKS12)
Hi all,
As discussed on Discord, I’ve run the full cleaning pipeline on the BeagleBoard dataset created by @fayezzouari sir, and here’s a breakdown of the results from the generated logs along with the benefits each stage brings:
[2026-01-02 17:19:23,272] INFO - Starting pipeline. Reading input from: c:\Users\Sanchit\OneDrive\Desktop\Hugging-Face Beagleboard\beagleboard-docs\Cleaning Scripts\multi-turn-conversations-t7ESxvRZkHn2-2025-12-07.json
[2026-01-02 17:19:23,947] INFO - Ingested 5674 raw conversations.
[2026-01-02 17:19:23,949] INFO - System prompt normalization complete: 0 inserted, 0 replaced.
[2026-01-02 17:19:23,949] INFO - Normalized system prompts.
[2026-01-02 17:19:23,949] INFO - Starting deduplication on 5674 conversations...
[2026-01-02 17:19:24,037] INFO - Removed 0 exact duplicates.
[2026-01-02 17:19:25,789] INFO - Use pytorch device_name: cuda:0
[2026-01-02 17:19:25,789] INFO - Load pretrained SentenceTransformer: all-MiniLM-L6-v2
[2026-01-02 17:19:56,454] INFO - Removed 629 semantically similar duplicates using threshold 0.9.
[2026-01-02 17:19:56,454] INFO - Deduplication complete. Final count: 5045 conversations.
[2026-01-02 17:19:56,511] INFO - Data size after deduplication: 5045
[2026-01-02 17:19:56,511] INFO - Running quality filter on 5045 conversations...
[2026-01-02 17:19:56,814] INFO - Dropped 0 conversations due to missing user/assistant roles.
[2026-01-02 17:19:56,814] INFO - Dropped 2213 due to low-quality assistant replies.
[2026-01-02 17:19:56,814] INFO - Dropped 4 due to very short user prompts.
[2026-01-02 17:19:56,814] INFO - Quality filter retained 2828 valid conversations.
[2026-01-02 17:19:56,814] INFO - Data size after quality filtering: 2828
[2026-01-02 17:19:56,814] INFO - Tagging metadata for 2828 conversations...
[2026-01-02 17:19:56,815] INFO - Use pytorch device_name: cuda:0
[2026-01-02 17:19:56,815] INFO - Load pretrained SentenceTransformer: all-MiniLM-L6-v2
[2026-01-02 17:20:43,572] INFO - Tagging complete. Total tags assigned across all conversations: 12779
[2026-01-02 17:20:43,572] INFO - Tags assigned to conversations.
[2026-01-02 17:20:43,572] INFO - Validating 2828 conversations with a max message limit of 10...
[2026-01-02 17:20:43,577] INFO - Validation complete. 2828 conversations passed the checks.
[2026-01-02 17:20:43,577] INFO - Data size after validation: 2828
[2026-01-02 17:20:43,577] INFO - Splitting 2828 conversations into chunks of max 2 QA pairs each...
[2026-01-02 17:20:43,587] INFO - Total split conversations created: 5656
[2026-01-02 17:20:43,587] INFO - Data size after multi-turn splitting: 5656
[2026-01-02 17:20:43,587] INFO - Tagging metadata for 5656 conversations...
[2026-01-02 17:20:43,588] INFO - Use pytorch device_name: cuda:0
[2026-01-02 17:20:43,588] INFO - Load pretrained SentenceTransformer: all-MiniLM-L6-v2
[2026-01-02 17:21:51,766] INFO - Tagging complete. Total tags assigned across all conversations: 20048
[2026-01-02 17:21:51,766] INFO - Tags reassigned after splitting.
[2026-01-02 17:21:52,084] INFO - Exported cleaned dataset to: c:\Users\Sanchit\OneDrive\Desktop\Hugging-Face Beagleboard\beagleboard-docs\Cleaning Scripts\clean_multi-turn-conversations-t7ESxvRZkHn2-2025-12-07.json
[2026-01-02 17:21:52,084] INFO - Final dataset contains 5656 conversation samples.
56740629> 0.9 threshold)221342828565620048 totalYou can also view the dataset on the HF here SanchitKS12/beagleboard-docs at cleaned-dataset-pr
Looking forward to any feedback or suggestions !!
Thanks alot !!
— Sanchit