The kernel error "omap_hsmmc 481d8000.mmc: error -110 requesting status" seems to cause an about 600 ms delay in the Linux kernel interrupt management system on BeagleBone Blue.
Sometimes my EduMIP balanced robot fell down. After investigations, I found that this coincides exactly with this kernel error (displayed by dmesg -Hw or logged in /var/log/kern.log):
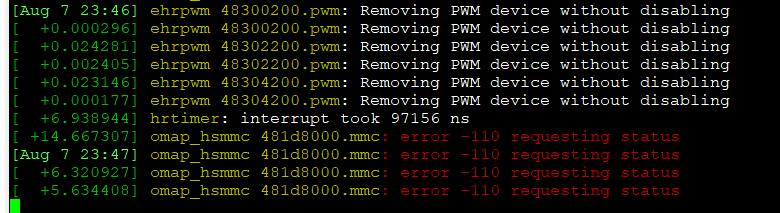
This error is more likely to occur if the usage (read-write loading) of the emmc is high. In the case of a balanced robot or unmanned helicopter controlled by the BeagleBone Blue (near real time regulation system) it could have quite bad effects…
The EduMIP’s the control loop is operated on a MPU9259 interrupt, at a frequency of 100 Hz (in rc_balance program of librobotcontrol). This would mean that when this error occurs, the kernel freezes for about 0.566 s, which is sufficient for the robot to fall or for the controlled helicopter to crash.
My special version of the rc_balance program, logs the sampled data with a timestamp. Below is a graph illustrating the time delay induced by the error:
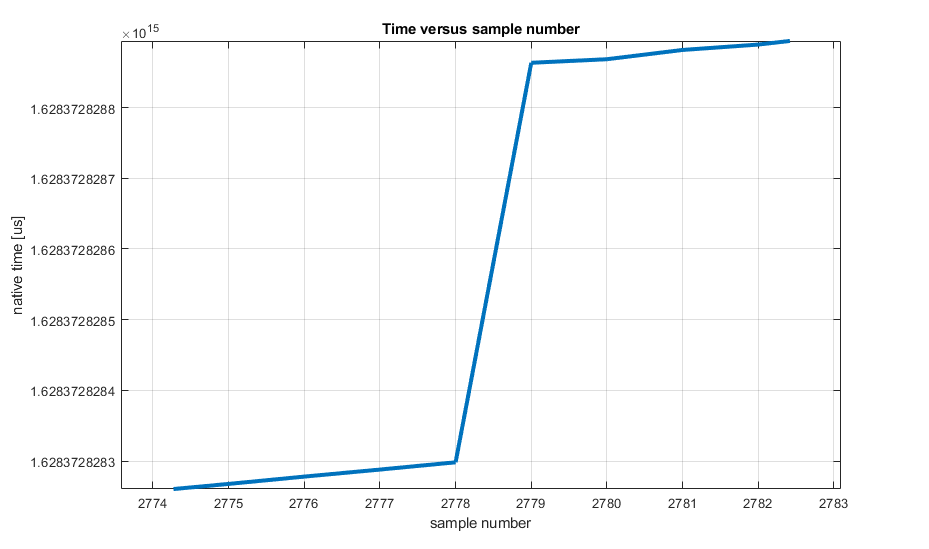
I tested with kernel version 4.19.94-ti-rt-r64 but I also with former versions of ti-rt kernels without success. Because this error can be found on some old BeagleBone-related posts dealing with other issues, I can deduct that this error exists on some devices for a long time.
How did I solved-it?
After some research, I oriented myself towards a problem with the driver for the OMAP2430 / 3430 MMC controller, probably managed by a code more or less similar:
After looking into the code above, I was unable to understand exactly what was going on. However, a plausible hypothesis was that it might be related to a low level disk error, for example when reading or writing to a bad block of the device.
Therefore, I tried to check the disk for bad blocks using a non-destructive read-write method, letting the diagnostic program repair automatically: if any bad blocks are found, then they are added to the bad block inode to prevent them from being allocated to a file or directory.
For this purpose
- I booted on the eMMC
- Mounted a flashing SD card
- Commented the flashing script (at the end of the boot/uEnv.txt of the SD card)
- Rebooted
- Listed, then checked the eMMC partition:
root@edumip:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
mmcblk0 179:0 0 14.9G 0 disk
└─mmcblk0p1 179:1 0 14.9G 0 part /
mmcblk1 179:8 0 3.6G 0 disk
└─mmcblk1p1 179:9 0 3.6G 0 part
mmcblk1boot0 179:16 0 4M 1 disk
mmcblk1boot1 179:24 0 4M 1 disk
root@edumip:~# e2fsck -cc -p -t -v /dev/mmcblk1p1
rootfs: Updating bad block inode.
79793 inodes used (34.19%, out of 233392)
48 non-contiguous files (0.1%)
59 non-contiguous directories (0.1%)
# of inodes with ind/dind/tind blocks: 0/0/0
Extent depth histogram: 75372/13
502502 blocks used (53.87%, out of 932864)
0 bad blocks
1 large file
65868 regular files
9424 directories
0 character device files
0 block device files
0 fifos
0 links
4492 symbolic links (4400 fast symbolic links)
0 sockets
------------
79784 files
Memory used: 804k/0k (75k/730k), time: 1420.69/ 2.48/ 0.77
I/O read: 72MB, write: 1MB, rate: 0.05MB/s
After this operation, I powered OFF the device, extracted the SD card and booted again from the eMMC. I tested by letting the robot balance for hours between yesterday and today, compiled a while ArduPilot version, etc… I haven’t encountered the problem since!  .
.
Strange thing however: although the checking procedure seems to have been effective, the dumpe2fs -b /dev/mmcblk1p1 don’t report any bad blocks in the filesystem…
Hope it helps! 
Vlad