This thread will serve as a place to follow along with the Running Machine Learning Models on Bela GSoC 2022 project.
Intro video: Ezra Pierce - Deep Learning for Bela - Workshop on Embedded AI for NIME - NIME 2022 - YouTube
This thread will serve as a place to follow along with the Running Machine Learning Models on Bela GSoC 2022 project.
Intro video: Ezra Pierce - Deep Learning for Bela - Workshop on Embedded AI for NIME - NIME 2022 - YouTube
This project aims to develop performance analysis tooling for Bela, this will eventually include profiling and benchmarking. For the first few weeks the focus has been on setting up a developer workflow to be able to translate high-level models (PyTorch, TFLite) to the Bela platform. The initial investigations have been involving the Intermediate Representation Execution Environment from Google (GitHub - iree-org/iree: A retargetable MLIR-based machine learning compiler and runtime toolkit.). The IREE project uses MLIR (https://mlir.llvm.org/) to build an ML compiler and runtime environment for heterogeneous hardware. This tool was chosen for evaluation due to it’s flexible nature (able to provide support for both the BBB and newer archs like BBAI64 & it’s accelerators) and support for various high-level frontends. It also has support for benchmarking using google benchmark and profiling using the Tracy profiler. The IREE runtime will be compared to other approaches so far attempted on the Bela, namely the DeepLearningForBela project, GitHub - rodrigodzf/DeepLearningForBela.
The first few weeks were used to setup a toolchain for building ML models on Bela using libtorch, TFLite and IREE, with the goal of comparing the different options.
Current task being worked on: Running ‘iree-benchmark-module’ with test MLP model on Bela. Planning on making a decision next Wednesday the 13th on whether or not to pursue IREE support.
Current task: Writing IREEFrontend class to be used for benchmarking in DeepLearningForBela project.
This task will be done by Wednesday July 13th to allow for the comparing of benchmarks between IREE and other approaches.
Successfully built iree-benchmark-module for Bela and benchmarked simple MLP model, resulting in a measurement of 26.2 ms over 1000 iterations. For comparison the lowest latency seen thus far using DeepLearningForBela measured for the same model was 20.59ms using TFLite & XNNPACK, while libtorch with mobile optimizations on was 59.27ms. This benchmarking looks promising so will be pursued further by trying out different model architectures this week.
Started new git repo for an IREE on Bela docker container which will include cross-compilation tools, precompiled IREE tools and build system for cross-compiling IREE projects: GitHub - ezrapierce000/bela-iree-container: Dockerized cross-compilation and Machine Learning Tools for Bela
TODO this week:
Finish writing setup instructions for others to recreate my benchmarks
Try benchmarking other models
Investigate new microkernel implementations (Lower VMVX linalg ops to microkernels. by stellaraccident · Pull Request #9662 · iree-org/iree · GitHub) and compare benchmarks
Improve issue management of project on github
Setup BBAI64 (may end up doing this the week after)
Updated TODO for the week, in order of priority:
Completed
Blockers
TODO
Took a couple days off so not many updates this week.
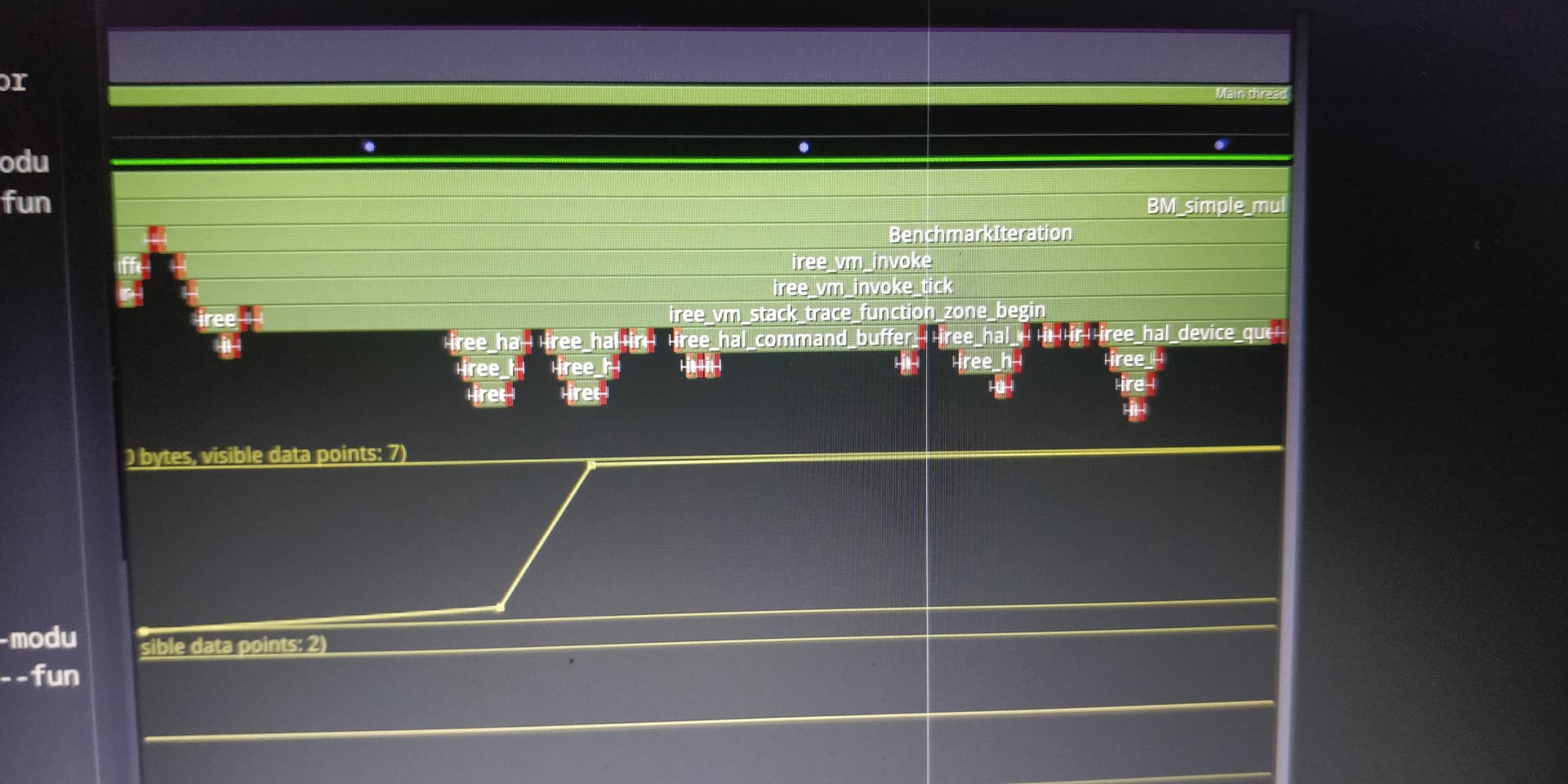
Example of Tracy being used on Bela:
Updated IREE to latest release, updated docker image accordingly
Took benchmarks of various models on Bela:
| Model | Export to VMFB | Bela IREE Benchmark |
|---|---|---|
| basic_mlp | Yes | 24.8ms |
| resnet_1d | No - IREE compile fails | NA |
| simple_conv_1d | Yes | 2549ms |
| simple_rnn | No - Can’t export to TF or TOSA | NA |
| single_mm | Yes | 19.7ms |
| siren_mlp | Yes | 802ms |
| transformer_block | Yes | Segmentation fault |
| variational_encoder | No - Can’t export to TF or TOSA | NA |
Back from vacation this week, the deadline for this project has been extended to September 26th. The following three weeks will be focused on documentation, organization and demos of the different IREE & ML tools set up during this project. With the final deliverable allowing people to benchmark and record profiles of their ML workloads on Bela/BBB. I will also be updating a dashboard for current model benchmarks on the BBB.
| Model | Export to VMFB | Bela IREE Benchmark |
|---|---|---|
| basic_mlp_1024 | Yes | 24.8ms |
| resnet_1d_1024 | Yes | NA |
| simple_conv_1d_1024 | Yes | 2549ms |
| simple_rnn | No - Can’t export to TF or TOSA | NA |
| single_mm_1024 | Yes | 19.7ms |
| siren_mlp_1024 | Yes | 802ms |
| transformer_block | Yes | Segmentation fault |
| variational_encoder | No - Can’t export to TF or TOSA | NA |
| single_mm_256 | Yes | 0.593ms |
| simple_conv_1d_256 | Yes | 1176ms |
| siren_mlp_256 | Yes | 200ms |