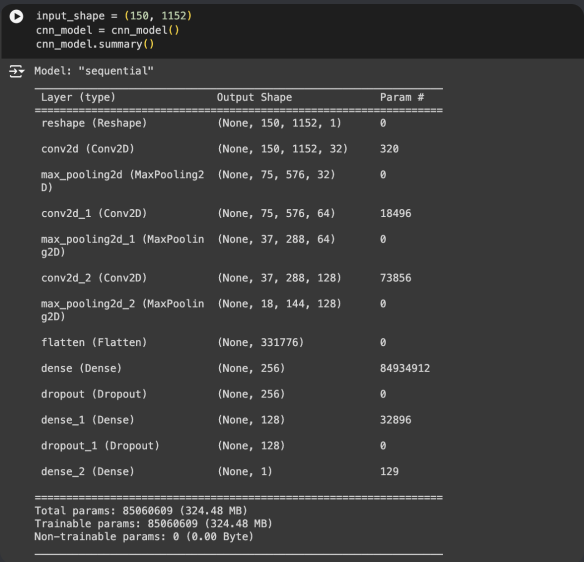
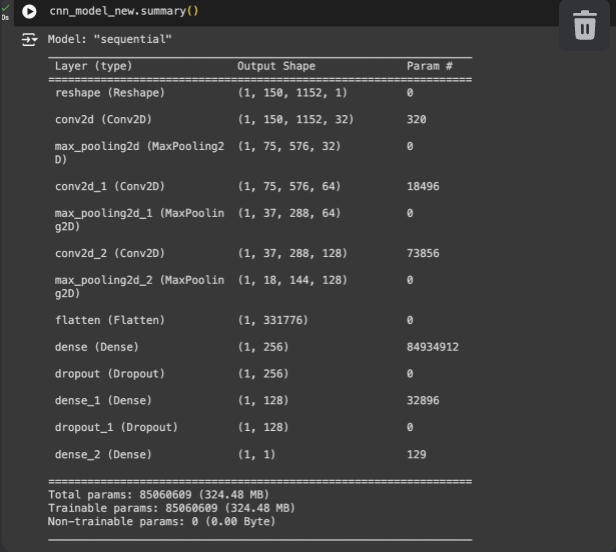
No, there were no complaints. Here is the compilation code I used. Do you think I missed anything?
# origin: https://github.com/TexasInstruments/edgeai-tidl-tools/blob/master/examples/osrt_python/tfl/tflrt_delegate.py
import yaml
import json
import shutil
import os
import argparse
import tflite_runtime.interpreter as tflite
import numpy as np
from PIL import Image
parser = argparse.ArgumentParser()
parser.add_argument("-c", "--config", help="Config JSON path", required=True)
parser.add_argument("-d", "--debug_level", default=0, help="Debug Level: 0 - no debug, 1 - rt debug prints, >=2 - increasing levels of debug and trace dump", required=False)
args = parser.parse_args()
os.environ["TIDL_RT_PERFSTATS"] = "1"
with open(args.config) as f:
config = json.load(f)
required_options = {
"tidl_tools_path": os.environ["TIDL_TOOLS_PATH"],
"artifacts_folder": "artifacts",
}
optional_options = {
"platform": "J7",
"version": " 7.2",
"tensor_bits": 8,
"debug_level": args.debug_level,
"max_num_subgraphs": 16,
"deny_list": "",
"accuracy_level": 1,
"advanced_options:calibration_frames": 2,
"advanced_options:calibration_iterations": 5,
"advanced_options:output_feature_16bit_names_list": "",
"advanced_options:params_16bit_names_list": "",
"advanced_options:quantization_scale_type": 0,
"advanced_options:high_resolution_optimization": 0,
"advanced_options:pre_batchnorm_fold": 1,
"ti_internal_nc_flag": 1601,
"advanced_options:activation_clipping": 1,
"advanced_options:weight_clipping": 1,
"advanced_options:bias_calibration": 1,
"advanced_options:add_data_convert_ops": 0,
"advanced_options:channel_wise_quantization": 0,
}
def gen_param_yaml(artifacts_folder_path, config):
layout = "NCHW" if config.get("data_layout") == "NCHW" else "NHWC"
model_file_name = os.path.basename(config["model_path"])
dict_file = {
"task_type": config["model_type"],
"target_device": "pc",
"session": {
"artifacts_folder": "",
"model_folder": "model",
"model_path": model_file_name,
"session_name": config["session_name"],
},
"postprocess": {
"data_layout": layout,
},
"preprocess": {
"data_layout": layout,
"mean": config["mean"],
"scale": config["scale"],
}
}
with open(os.path.join(artifacts_folder_path, "param.yaml"), "w") as file:
yaml.dump(dict_file, file)
if config["session_name"] in ["tflitert", "onnxrt"]:
shutil.copy(config["model_path"], os.path.join(artifacts_folder_path, model_file_name))
def infer_image(interpreter, image_files, config):
input_details = interpreter.get_input_details()
floating_model = input_details[0]['dtype'] == np.float32
batch = input_details[0]['shape'][0]
height = input_details[0]['shape'][1] # 150
width = input_details[0]['shape'][2] # 1152
# Initialize input_data array with the shape [batch, height, width]
input_data = np.zeros((batch, height, width), dtype=np.float32)
# Process calibration arrays
for i in range(batch):
img = np.load(image_files[i]) # Load numpy array directly
if img.shape != (height, width):
raise ValueError(f"Array {image_files[i]} has shape {img.shape}, expected ({height}, {width})")
input_data[i] = img
# Ensure input data type matches the model’s requirement
if not floating_model:
input_data = np.uint8(input_data)
config['mean'] = [0]
config['scale'] = [1]
interpreter.resize_tensor_input(input_details[0]['index'], [batch, height, width])
interpreter.allocate_tensors()
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
def compose_delegate_options(config):
delegate_options = {}
delegate_options.update(required_options)
delegate_options.update(optional_options)
if "artifacts_folder" in config:
delegate_options["artifacts_folder"] = config["artifacts_folder"]
if "tensor_bits" in config:
delegate_options["tensor_bits"] = config["tensor_bits"]
if "deny_list" in config:
delegate_options["deny_list"] = config["deny_list"]
if "calibration_iterations" in config:
delegate_options["advanced_options:calibration_iterations"] = config["calibration_iterations"]
delegate_options["advanced_options:calibration_frames"] = len(config["calibration_images"])
if config["model_type"] == "od":
delegate_options["object_detection:meta_layers_names_list"] = config["meta_layers_names_list"] if (
"meta_layers_names_list" in config) else ""
delegate_options["object_detection:meta_arch_type"] = config["meta_arch_type"] if (
"meta_arch_type" in config) else -1
if ("object_detection:confidence_threshold" in config and "object_detection:top_k" in config):
delegate_options["object_detection:confidence_threshold"] = config["object_detection:confidence_threshold"]
delegate_options["object_detection:top_k"] = config["object_detection:top_k"]
return delegate_options
def run_model(config):
print("\nRunning_Model : ", config["model_name"], "\n")
# set delegate options
delegate_options = compose_delegate_options(config)
# delete the contents of this folder
os.makedirs(delegate_options["artifacts_folder"], exist_ok=True)
for root, dirs, files in os.walk(delegate_options["artifacts_folder"], topdown=False):
[os.remove(os.path.join(root, f)) for f in files]
[os.rmdir(os.path.join(root, d)) for d in dirs]
calibration_images = config["calibration_images"]
numFrames = len(calibration_images)
# set interpreter
delegate = tflite.load_delegate(os.path.join(
delegate_options["tidl_tools_path"], "tidl_model_import_tflite.so"), delegate_options)
interpreter = tflite.Interpreter(
model_path=config["model_path"], experimental_delegates=[delegate])
# run interpreter
for i in range(numFrames):
start_index = i % len(calibration_images)
input_details = interpreter.get_input_details()
batch = input_details[0]["shape"][0]
input_images = []
# for batch > 1 input images will be more than one in single input tensor
for j in range(batch):
input_images.append(
calibration_images[(start_index+j) % len(calibration_images)])
infer_image(interpreter, input_images, config)
gen_param_yaml(delegate_options["artifacts_folder"], config)
print("\nCompleted_Model : ", config["model_name"], "\n")
run_model(config)
Gitlab link of code: Link