Sure, will try that.
Minutes of Meeting(05-08-2024)
Attendees:
Key Points:
- I provided updates about inferencing on the BBAI64. @lorforlinux suggested raising an issue in the TI forum if the problem continues.
- We discussed methods for data collection for real-time inferencing. I’ll start by collecting a dataset from a set-top box using an HDMI to USB converter. If that doesn’t work, I’ll try downloading YouTube live recorded videos that include advertisements.
- Since I don’t have access to an x86 laptop right now, I’ll initially attempt compilation inside a Docker container. If I encounter compatibility issues, I’ll switch to compiling in the GitLab runner.
I have resolved that kernel crashing error, the error was coming due to python and tflite_runtime version conflict. Now when I initialize the interpreter with custom delegate this is coming:
Number of subgraphs:1 , 11 nodes delegated out of 12 nodes
APP: Init ... !!!
MEM: Init ... !!!
MEM: Initialized DMA HEAP (fd=5) !!!
MEM: Init ... Done !!!
IPC: Init ... !!!
IPC: Init ... Done !!!
REMOTE_SERVICE: Init ... !!!
REMOTE_SERVICE: Init ... Done !!!
8803.328634 s: GTC Frequency = 200 MHz
APP: Init ... Done !!!
8803.328715 s: VX_ZONE_INIT:Enabled
8803.328724 s: VX_ZONE_ERROR:Enabled
8803.328733 s: VX_ZONE_WARNING:Enabled
8803.329329 s: VX_ZONE_INIT:[tivxInitLocal:130] Initialization Done !!!
8803.329407 s: VX_ZONE_INIT:[tivxHostInitLocal:86] Initialization Done for HOST !!!
It is stuck here and not moving forward
- No additional messages are printed in dmesg beyond the initial boot (16 seconds in).
dmesg for reference:
kernel_logs.txt (54.2 KB) - Remote cores logs (captured from
/opt/vision_apps/vx_app_arm_remote_log.out tool)
remoteCores_logs.txt (17.3 KB)
This appears to be the issue:
C7x_1 ] 1243.288393 s: VX_ZONE_ERROR:[tivxAlgiVisionAllocMem:184] Failed to Allocate memory record 5 @ space = 17 and size = 170281740 !!!
Week 9 Updates:
- Read complete documentation of TIDL
- Resolved the kernel restart error. The TIDL release(08_02) which I am using, expects very specific version of tflite_runtime and python. So, I downgraded to python3.7 and tflite_runtime=2.07 to run the inferencing.
- Now, when I load the interpreter with a custom delegate I am getting error mentioned in the previous post.
- Week 6-7 Blog out. Link
- Tested dataset recording setup from Set Up Box and it is working perfectly.
Dataset Collection setup from Set Up Box(Click to expand)
Requirements: HDMI to HDMI cable, HDMI to USB Video capture card.- Connected hdmi output of the Set Up Box to Video capture card using hdmi to hdmi cable and then connected it to my macbook using a dongle which converts usb to Type C output.
- Recorded Video and audio using OBS studio and it is working.
Blockers
- Blocker would be inferencing definetely. Still stuck in it.
Next Week Goals
- Collecting dataset from Set Up Box
- Try generating artifacts in TI Edge AI cloud and then perform inferencing there.
- Train a very minimal model and then try inferencing using it.
- Trying to resolve the current error. Maybe I will try to change the system memory map to accommodate large requests from model.
1 Like
@Illia_Pikin, what was the size of your TFLite model? I’m trying to determine if the issue could be related to the model’s size.
I don’t think the issue is related to compilation:
This is the runtime_visualization.svg and
and 26_tidl_net.bin.svg formed by the compilation script. They both seems correct. This would mean that the compilation is indeed successful.

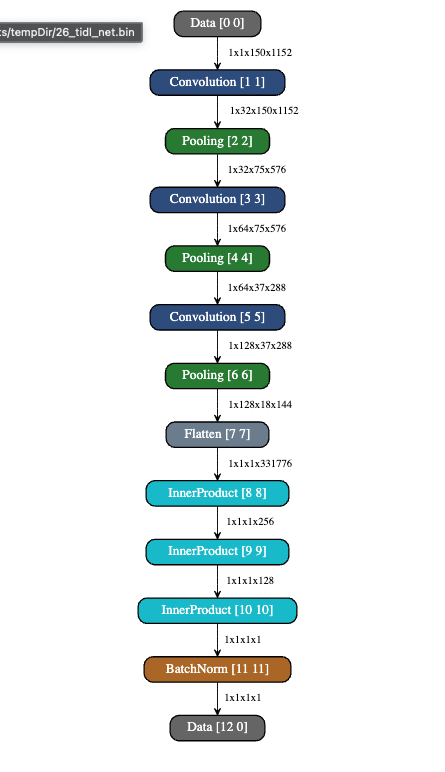
I just used the transfer learning with ssd_mobilenet_v2_coco_2018_03_29 from tf1_detection_zoo
That model was in the list of “TI supported models”
Alright!
Minutes of Meeting(12-08-2024)
Attendees:
Key Points:
- We discussed about the error encountered during initialization of interpreter with custom_delegate on the BeagleBone AI-64.
- Since the model is currently running on the BB AI-64’s CPUs, @lorforlinux suggested to focus on preparing a pipeline that can be used across all boards.
- To optimize inference on CPUs and minimize latency, @lorforlinux recommended conducting inference after a specific timestamp and storing the results along with their timestamps in a data structure. Once inference for the entire video is complete, the video should be displayed all at once using the stored results. This approach aims to eliminate lag during video playback.
Tasks assigned:
- Build the input pipeline on my laptop and share the results with the community. Simultaneously, address the error with support from the e2e forum community.
- Begin developing the video feed pipeline for the BeagleBone AI-64.
First, I’ll focus on getting the pipeline to run on the BeagleBone AI-64’s CPUs. Once that’s complete, I’ll work on implementing it with the onboard DSPs and DL Accelerators.
Week 10 Updates:
- Collected a 10GB dataset from a Set-Top Box, including content and commercials from news, Olympic games, and dramas.
- Wrote the feature extraction code for videos, extracted audio-visual features, merged them, and performed inference. This code extracts features and pre-processes them so they can be fed into the model for inference.
Details of Visual Feature Extraction from Videos (Click to expand)
- Load the InceptionV3 model, TFLite model, and PCA parameters.
- Resize the frame, preprocess it, and extract features using InceptionV3.
- Process the video in chunks of 150 frames and extract features.
- Apply PCA, 8-bit quantize the features, and perform inference.
Details of Audio Feature Extraction from Videos (Click to expand)
- Download the VGGish model, load the checkpoint, and freeze the graph for feature extraction.
- Use FFmpeg to extract audio from the given video file.
- Load the audio file, convert it to mono, and resample it to the target sample rate.
- Compute the Short-Time Fourier Transform (STFT) and convert it to a log-mel spectrogram.
- Load the frozen VGGish model and extract audio features from the spectrogram.
- Normalize the extracted features and quantize them to 8-bit integers. They are now ready.
Workflow:
The video is loaded from its file, and frames are recorded at intervals of 250ms (i.e., 4 frames per second). After collecting 150 frames (150/4 = 37.5 seconds), inference is performed. The result of the inference is stored in a tuple, which contains the label, start frame and end frame at the rate the video is loaded (not at 4 frames per second to avoid a flickery output video). After performing inference and storing the results for all video frames in chunks of 150 frames, the output video is displayed. When the label for a frame is 0 (non-commercial), the frame is displayed as it is. However, when the label for a frame is 1 (commercial), a black screen is shown instead.
Note
Initially, when I followed this workflow and started performing inference on videos, I realized that extracting audio features was taking significantly longer compared to visual features. For example, for a 30-second video, visual features were extracted in 30-35 seconds, but audio features took 5 minutes for the same. Therefore, I decided to exclude audio features, as the accuracy was similar with or without them. I trained a new CNN model using only visual features (shape: (150, 1024)). (1152-128 = 1024). The results below are based on that model.
Results:
I tested the complete pipeline on three videos. One was a random commercial video downloaded from YouTube, another was a non-commercial news video, and the last was a mix of commercial and non-commercial content (drama + commercial). (Small chunks of compressed videos are included with the results.)
-
Results on a random commercial-video:
Video length: 150 seconds.
Processing time: 151 seconds.
Accuracy: 80%
-
Results on non-commercial video(news):
Video length: 176 seconds.
Processing time: 186 seconds
Accuracy: 80%
-
Results on Mix Video(dramas+Commercial):
Video length: 30 mins
Processing time: 33-34 mins
Accuracy: 65-70%
Here, see how the transition at 1:20 happens when commercial gets over and drama get started.
-
Above video after post-processing:
(Sorry for the bad quality of videos, but I had to compress the videos to 2% of its original size so I could post it here)
There is a slight decrease in FPS, but it is barely noticeable.
I’m currently running this on my system and will be testing it on the BeagleBone AI-64 next.
Week 11 Updates
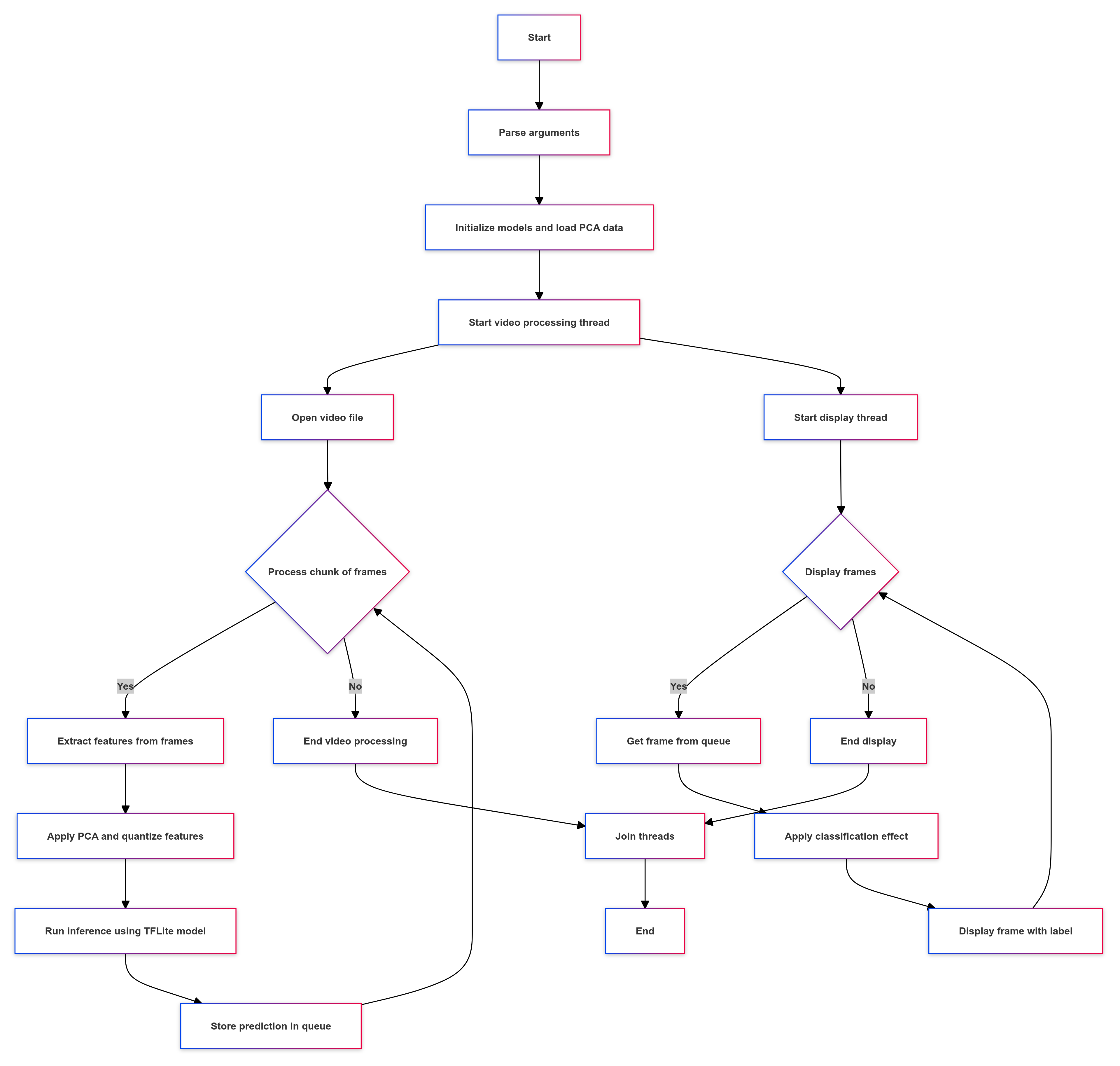
- Successfully implemented a real-time processing pipeline on the BeagleBone AI-64. Previously, the process involved handling the entire video before displaying it. Now, I’ve transitioned to a real-time approach using Python’s threading module.
Workflow
The pipeline consists of two threads. The main thread is responsible for display, while the processing thread captures input from the VideoCapture device and processes it. Frames are continuously added to a queue as they come in. Every second, four frames are selected at 250ms intervals. Once 150 frames have been collected at a rate of 4fps, inference is performed, and the results are displayed by the main thread using the frame queue. Meanwhile, the processing of the next set of frames occurs in the second thread simultaneously.
Results
- Laptop: The pipeline is extremely fast, maintaining continuity. It takes 1 minute to process the initial chunk of frames. As soon as the display of the first chunk begins (at >35fps), processing of the next chunk starts concurrently. By the time the first chunk finishes displaying, the second chunk’s processing is complete, and the third chunk’s processing is already underway, ensuring continuous display.
- BeagleBone AI-64: The results show significant improvement over the previous approach of processing the entire video before displaying it. The first chunk of frames is ready in 7 minutes. With the display set at 7fps, continuity is maintained, allowing smooth viewing after the initial 7 minutes without any lag.
Blockers:
On the laptop, processing happens much faster than displaying, leading to memory overhead due to the need to store processed frames. For a 10-minute video, this causes memory limits to be exceeded, resulting in a process crash. This can be mitigated by pausing processing intermittently to allow the display to catch up.
Post-GSoC Plans
The official GSoC coding period ends on the 26th of this month, but I plan to continue exploring and improving my system on the BeagleBone AI-64.
Future Work:
- Running my custom model on the BeagleBone AI-64 using the DSPs and Accelerators(currently it is running on the CPUs). I’ve already raised an issue on the e2e forum for future reference.
- Enhancing the documentation for the BeagleBone AI-64 from an EdgeAI perspective, including adding verified TIDL benchmark examples and demonstrating their application on the BBAI64.
- In the future, if any project on BeagleBoard requires ML support for the BeagleBone AI-64 or BeagleY-AI, I would be more than happy to assist with that project.
3 Likes
- Week 9-10 Blog edgeai continued
- Week 11-12 Blog RealTimeInferencing
- Project Wiki Page: Blog Summarizing my work in GSoC 2024
1 Like